2.2 Importing Data
The most efficient way to get data into Xynk is to import it by copying from a spreadsheet program like Excel or Numbers, or by reading text delimited files (eg. comma-separated values (CSV) files or tab-separated values (TSV) files. Imported datasheets (either from text files or from the pasteboard) can be in either CSV or TSV format: Xynk will try to autodetect the delimiter, based on occurences of commas and tabs in the data.
As described below ("How To Import"), you can select and copy the data within Excel or Numbers, then have Xynk import the data from the pasteboard, or you can export and save the data from Excel or Numbers into a CSV or TSV text files and then import the file into Xynk.
Data Format
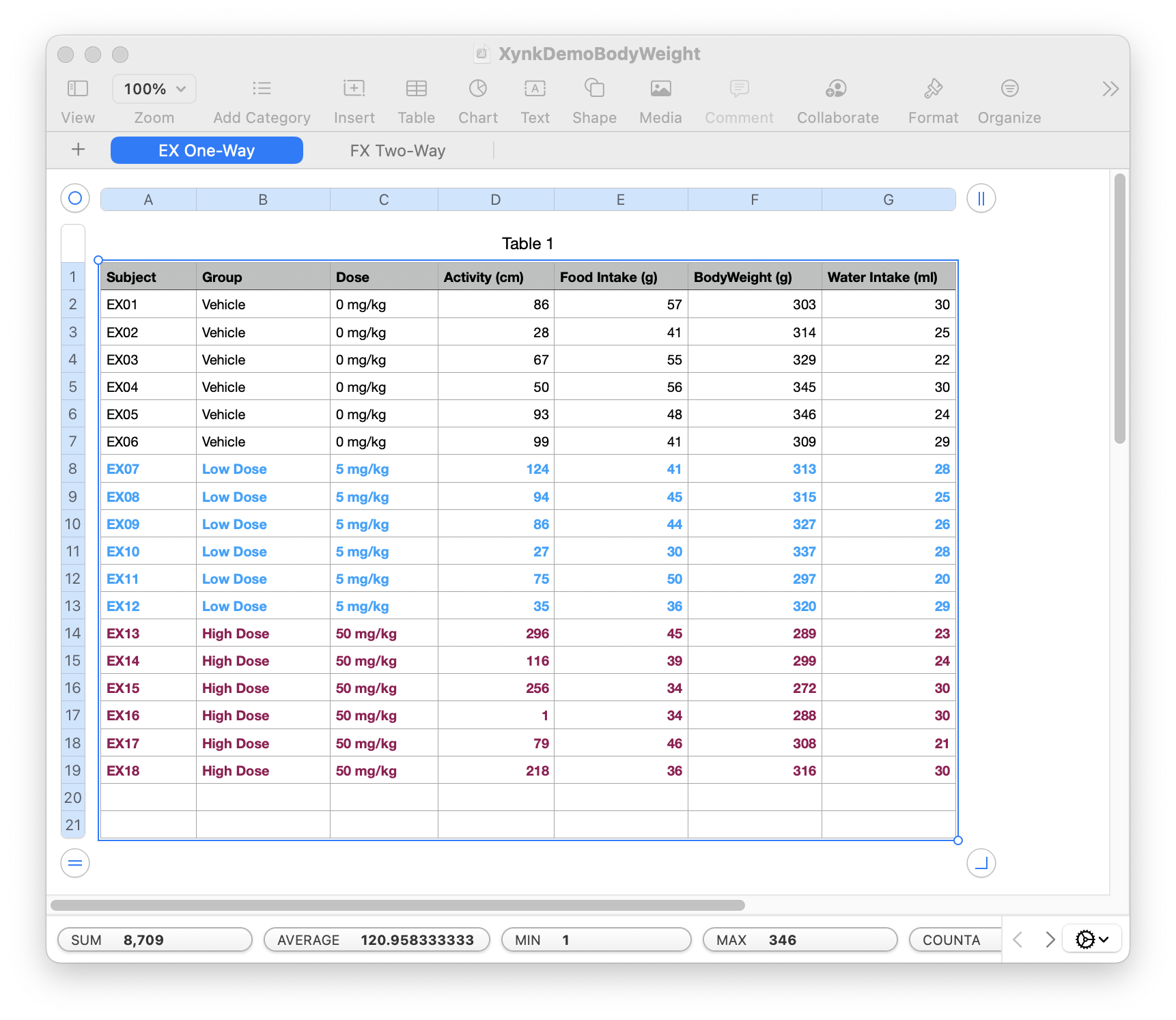
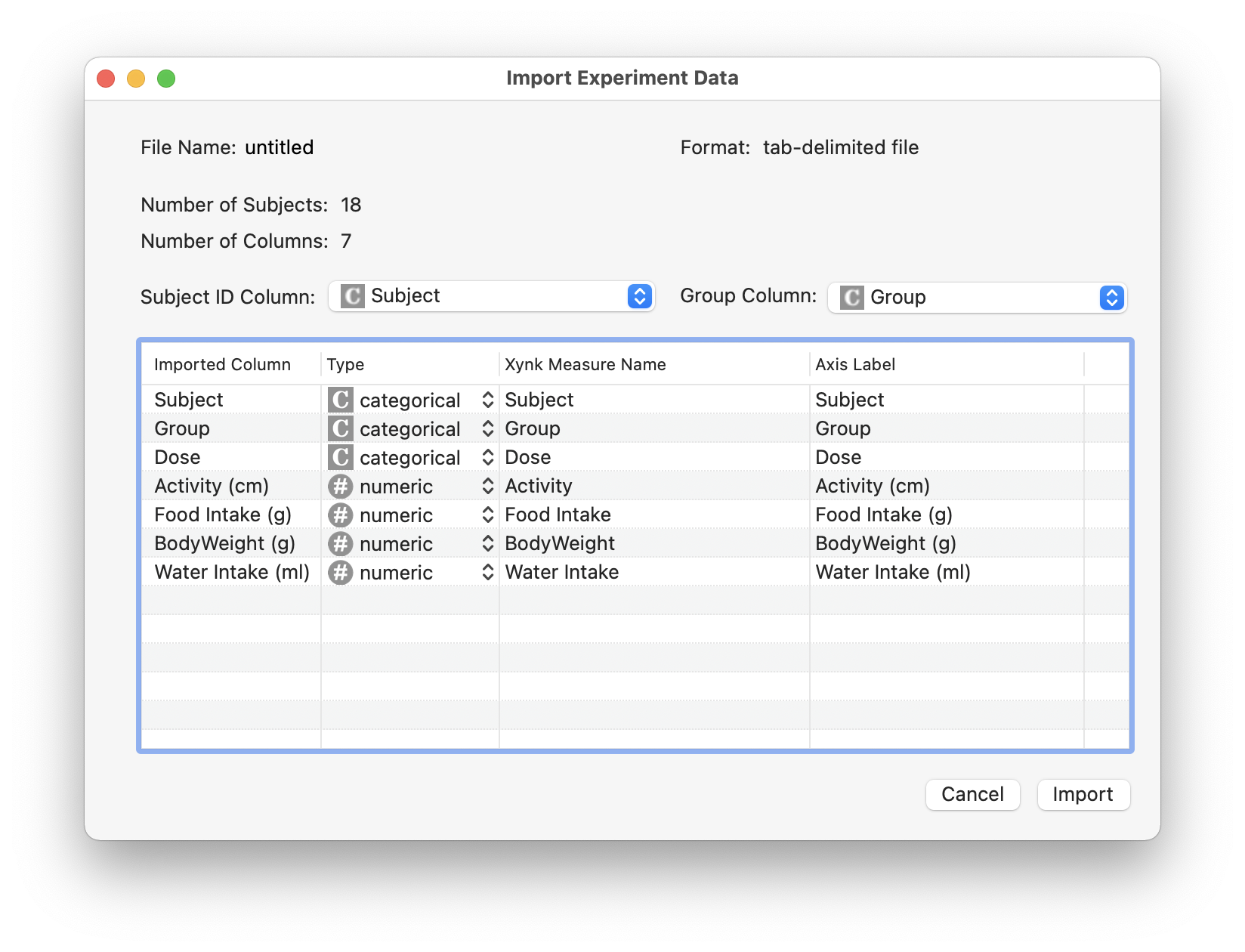
Data for import should be entered in a table or datasheet composed of a header row with the names of the measures (eg. "Subject", "Group", "Dose", "Activity (cm), ..."), followed by one row for every individual subject in the experiment. Optional units can be included in parentheses after the name of a column "<measure_name>(<units>)", e.g. "Food Intake (g)".
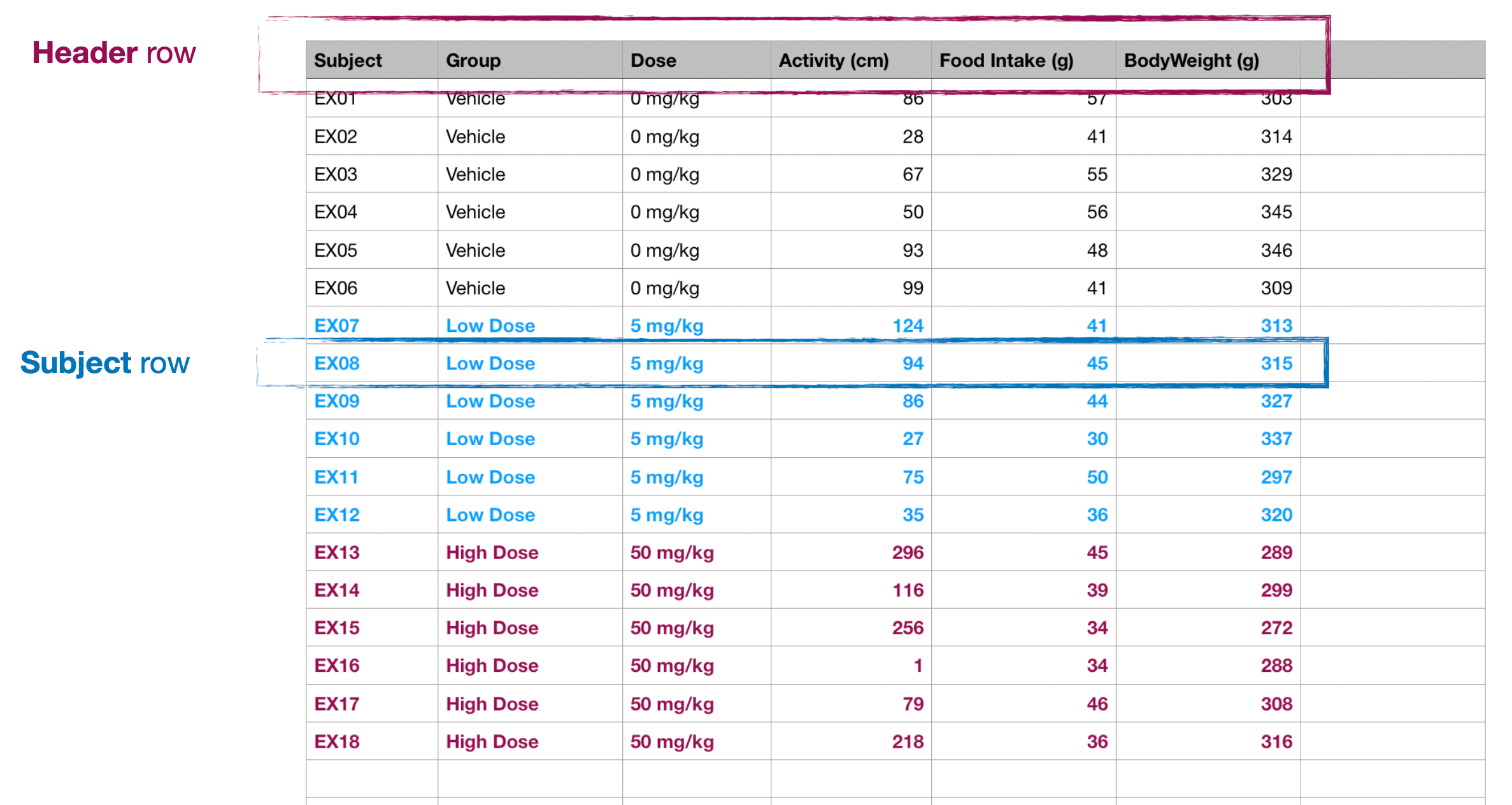
Measure Columns
Each column contains the value for either a categorical (independent) measure, or a numeric (dependent) measure. Categorical measure columns are identified because they contain text values (e.g. the "Group" column might contain "Control" or "Treatment" values), while numeric measure columns contain numbers (or a missing data string; see below). Note that whitespace is trimmed from start and end of text in every cell during import.
The first cell of each column should be the name of the measure.
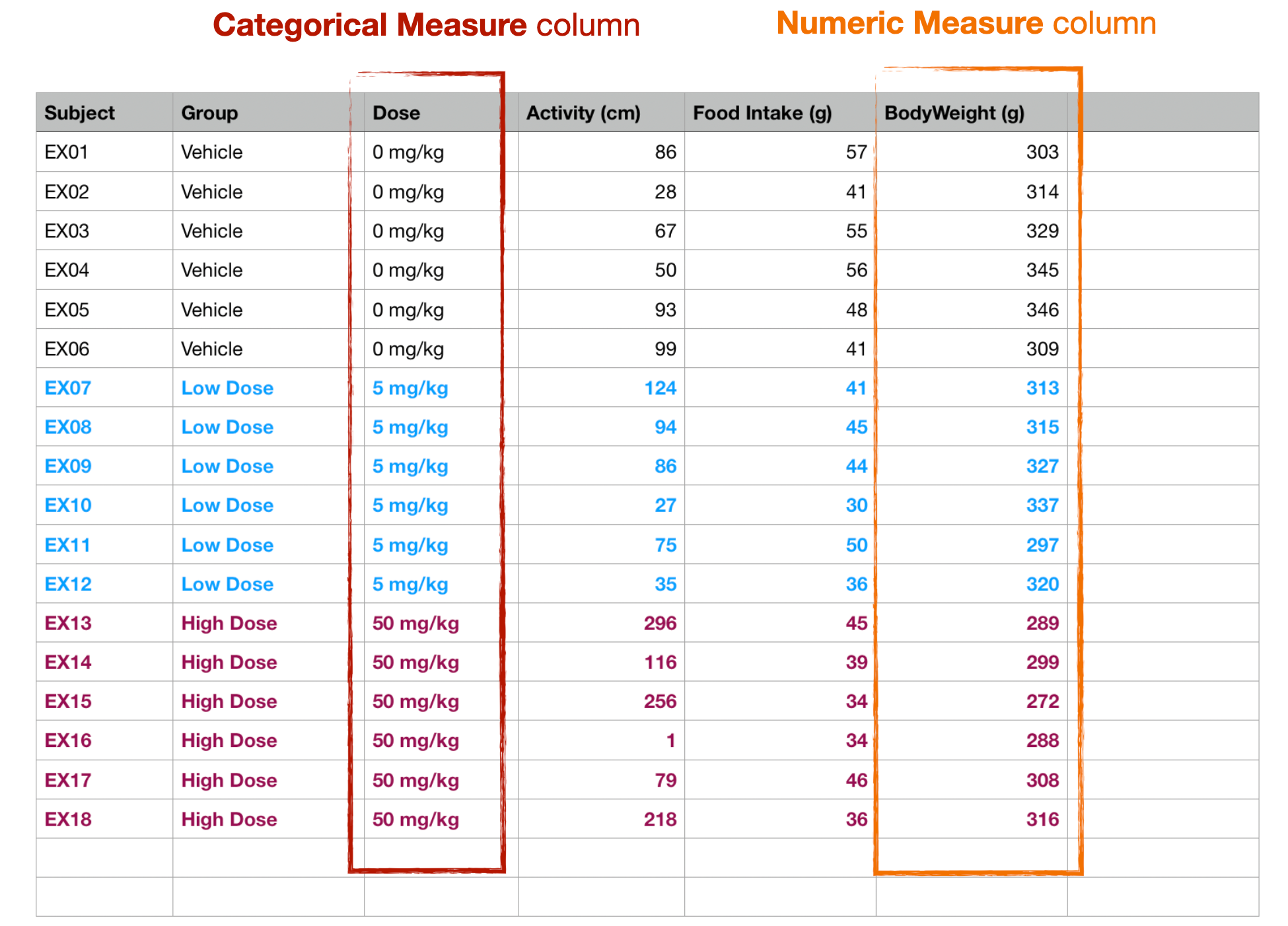
Thus, each cell at a row and column contains the value for that row's subject for that column's measure.
Subject and Group Columns
There must always be a "Subject" column and a "Group" column, both of them categorical measures, with values for each row of the datasheet.
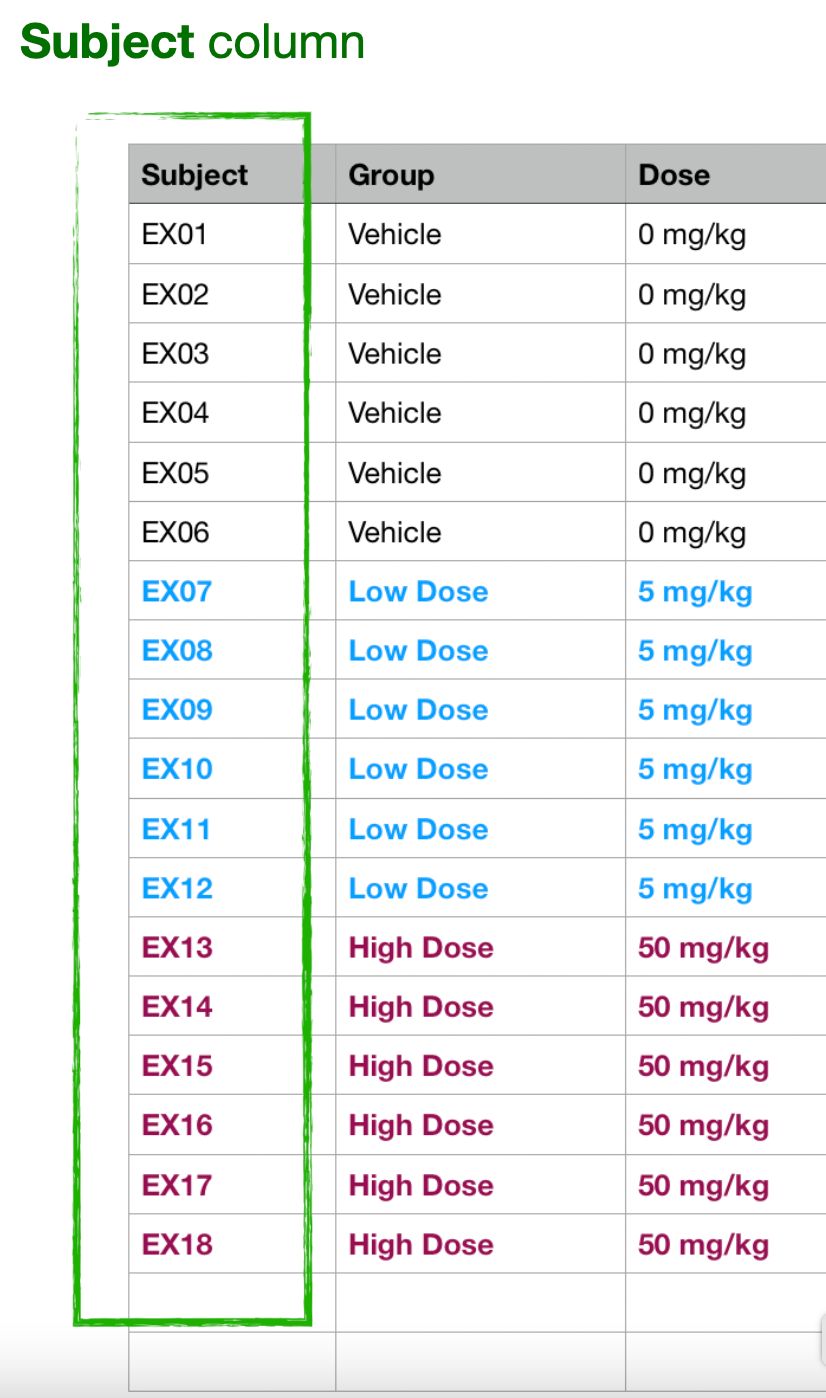
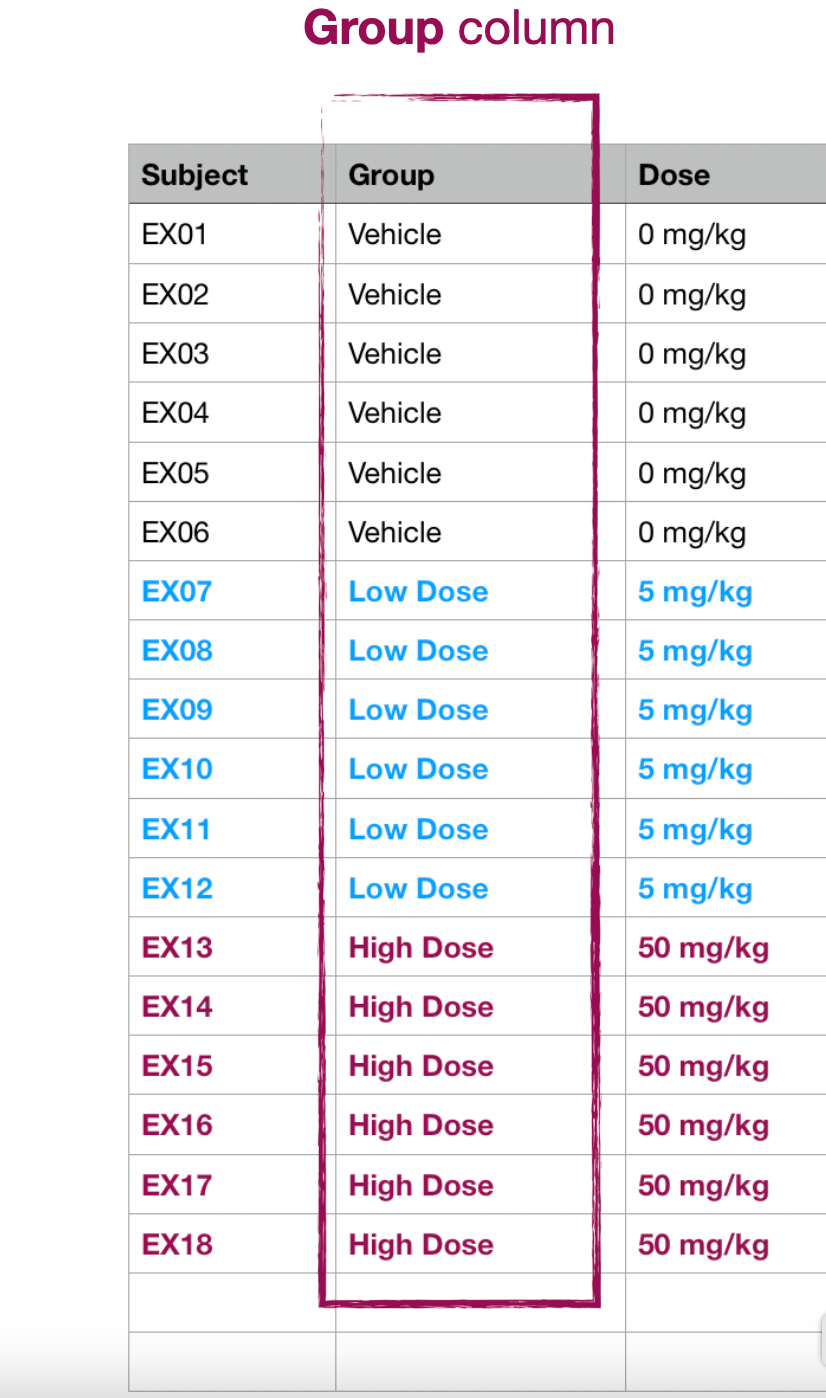
You don't have to name the columns "Subject" and "Group", but in the import dialog you will need to select and confirm which 2 columns identify the individual subject for each row, and the experimental group each subject belongs to.
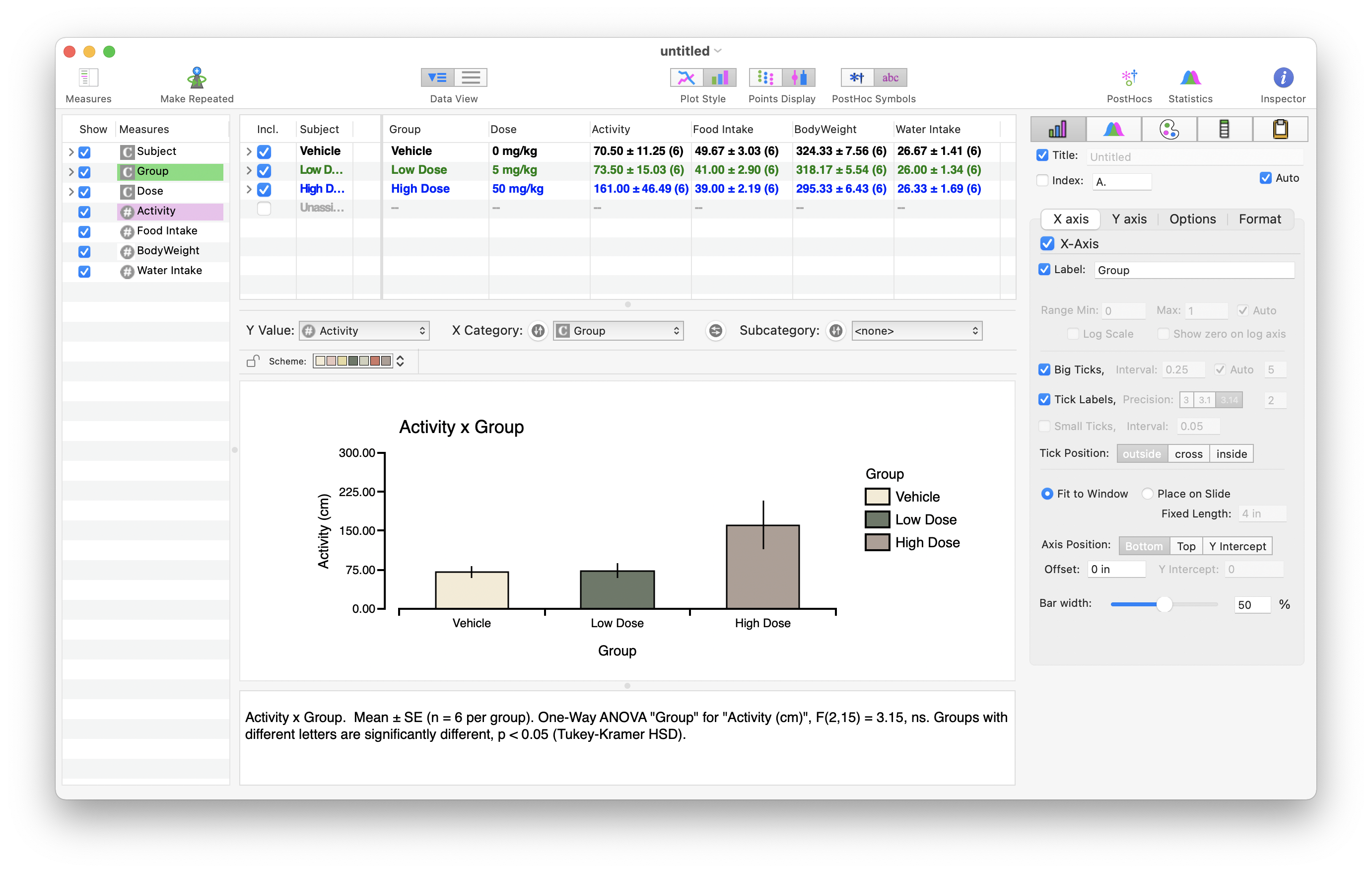
Example Import
More Details on Importing
Comment Rows
Any rows that begin with a octothorpe ("#") will be skipped and not read by Xynk, so that they can be used to hold comments. So additional notes or metadata can be included in the CSV or TSV text files in #-prefixed comment rows. (But note that data in commented rows is NOT imported and stored by Xynk.)
Missing Data
It is not uncommon for a datasheet to have instances of missing data, due to lapses in data collection or observation. Missing data values can be represented in cells by:
- leaving the cell blank (or filled with spaces)
- inserting one of the pre-defined "missing data" strings:
- "." (a single period)
- "--" (two dashes)
- "—"(em dash)
- "nd" or "n.d."
- "na" or "n.a."
- "nan"
- "nil"
- "null"
or you can specify a custom missing data string under Preferences -> Importing.
Repeated Measures
[NEED TO CORRECT to get rid of brackets] indicated with "<name_of_repeated_measure>[<ordinal>]::<measure_name>(<units>)" ordinal in square brackets are optional; units in parantheses are optional
NOTE: every thing after units in parantheses is ignored
DESIRED BEHAVIOR: read ordinal as last numeric string in the column title, keep in column name but remove parenthetical units.
e.g. "Repeated Weight::Body Weight (g) 1", "Repeated Weight::Body Weight (g) 2", "Repeated Weight::Body Weight (g) 3"
is read into Xynk as:
(R) Repeated Weight -- the repeated measure # Body Weight [1] -- the individual numeric measures making up the repeated measure # Body Weight [2] # Body Weight [3]
and "(g)" will be used as the units on the y-axis of the body weight graphs.
everything after units in parantheses (for example "(g)" for grams) is ignored, so additional identifiers in the source CSV file can be put there.
e.g. "Test Intakes::Intake (ml) 10/17/2021", "Test Intakes::Intake (ml) 10/16/2021", "Test Intakes::Intake (ml) 10/18/2021"
is read into Xynk as:
(R) Test Intakes # Intake [1] # Intake [2] # Intake [3]
e.g. "Repeated Weight[1]::Body Weight (g)", "Repeated Weight[2]::Body Weight (g)", "Repeated Weight[2]::Body Weight (g)",
e.g. "Repeated Weight::Body Weight 1", "Repeated Weight::Body Weight 2", "Repeated Weight::Body Weight 3",
y-axis label set to measure name of first repeated measure (without the bracketed ordinal label) (e.g "Body Weight (g)") x-axis label set to repeated measure name (e.g. "Repeated Weight") x-axis ordinal tick labels (ordinal labels) to bracketed ordinals, if present -- otherwise ordinal label is set to 1-indexed number of measure in the repeated measure.
set name of measures to measure_name (after ::) plus bracketed ordinal label
These can all be tweaked in measure inspector.